Regular Expressions
Regular Expressions (also well known as regex) allow us to search for a particular textual pattern. We use different kinds of symbols to create a regular expression, however, these symbols are universal for all programming languages. Using regex, some of the things we can ask Python to check is if the text has:
- if the word ‘fire’ exists in the text?
- if the text starts with ‘A’ or ‘a’?
- if the text has any whitespaces?
- if the text has any digits or letters?
- if the letters ‘will’ are in order inside the text?
We need to use a module called “re” to work with Regular Expressions in Python. Consider the following example:
import re
pattern_ = "[0-9]"
text = "This string has 01234 & 56789"
result = re.findall(pattern_, text)
print("Text with only digits")
print(result)
This will give the output as:

Let’s explore the above code, we created two variables called “pattern” and “text”. The “text” variable will store a string, on which we will perform varying operations using regular expressions. The “pattern” variable will store an expression and we will pass this variable as an argument for regex functions.
The “re” module provides a function called “findall” and as the name suggests will find all matches from the “text” variable based on the “pattern” variable. The output is then stored in the result variable.
If we alter the above code’s “pattern” variable as given below we would get another output.
pattern_ = "[0-9]+"
We get the output as:
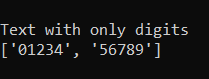
The ‘+’ in the pattern variable tells Python to not match it as just one digit at a time but to stop only when the next character is not a digit {it stops when it is not a number since we used [0-9]}. Consider the pattern:
pattern_ = "[a-z]+"
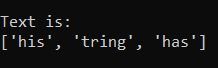
Here the pattern is [a-z] and Python will only return those matches that are lowercase strings. Also, since we have added a ‘+’ sign it will return an entire string instead of one letter at a time. Consider variants of the above pattern:
pattern_ = "[A-Z]+"
We get:
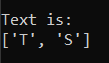
pattern_ = "[A-Za-z]+" # This will return uppercase and lowercase characters
We get:
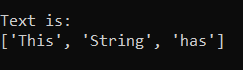
We can also use ‘^’ which tells Python to match everything other than the provided pattern. Consider the following pattern which matches everything other than an ‘i’, ‘a’, or ‘ ’ {whitespace}:
pattern_ = "[^ia ]+"
Thus, we get:

Patterns that are contained within [] are referred to as Character Classes, so consider the varying types of possibilities for Character Classes.
| Serial No. | Character Class | Description |
| 1. | [Vv] | Matches Verification or verification |
| 2. | R[au]n | Matches Run or Ran {the case is important; this does not match run or ran} |
| 3. | [^AEIOU] | Matches everything other than uppercase vowels |
We can also use Special Character Classes, which are essentially shortened versions of specific Character Classes. Consider the pattern:
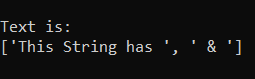
pattern_ = "\D+" # Which is equal to [^0-9]
This prints everything but numbers. So, the output would be:
Another pattern we can use is:
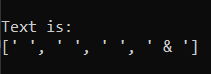
pattern_ = "\W+" # Which is equal to [^A-Za-z0-9_]
This prints everything but letters {uppercase & lowercase}, numbers, and underscores. Thus, the output would be:
You can also see the list of other special character classes.
| Serial No. | Special Character Class | Description |
| 1. | . | Matches everything except a newline |
| 2. | \d | Matches only digits = [0-9] |
| 3. | \s | Matches white space characters [\t\r\n\f] |
| 4. | \S | Matches everything except white space characters = [^\t\r\n\f] |
| 5. | \w | Matches all word characters = [A-Za-z0-9_] |
We also have repetition cases that we can use in Regular Expressions.
| Serial No. | Special Character Class | Description |
| 1. | blogs? | Matches “blog” or “blogs”, where ‘s’ is optional |
| 2. | technical* | Matches “technica” with 0 or more ‘l’ |
| 3. | content+ | Matches “conten” with 1 or more ‘t’ |
| 4. | \d{5} | Matches exactly 5 digits of a number |
| 5. | \d{5,} | Matches exactly 5 or more digits of a number |
| 6. | \d{5,7} | Matches exactly 5, 6, or 7 digits of a number |
Finally, let us consider the Anchors we can use with Regular Expressions.
NOTE: When using anchors, it is best to convert your pattern into raw text.
| Serial No. | Anchors | Description |
| 1. | ^Verification | Match “Verification” at the start of a string/line. |
| 2. | Verification$ | Match “Verification” at the end of a string/line. |
| 3. | \AVerification | Match “Verification” at the start of a string. |
| 4. | Verification\Z | Match “Verification” at the end of a string. |
| 5. | \bVerification\b | Matches the word “Verification” alone. |
| 6. | \bVerification\B | Returns all words that start with Verification but have something with it. It won’t match “Verification” alone but matches “VerificationMaster” or “Verifications” etc. |
| 7. | Verification(?=!) | Returns all words Verification if it ends with a ‘!’. It matches only if the word is “Verification!” |
| 8. | Verification(?!*) | Returns all words Verification if it does not end with ‘*’. It ignores all words that are “Verification*. |
What have we learned?
- What are Regular Expressions?
- What can we use Regular Expressions for?
- Which module can be used for Regular Expressions in Python?
- Which function finds all of the patterns of a string?
- What are some examples of the Character Classes we can use?
- What are the Special Character Classes we can use?
- What does the ‘+’ repetition case denote?
- What are the different types of Anchors?