Lock
Another important feature that we need to remember when using Threads is the mechanism of locking. Imagine if you are using multiple threads on a single resource, when one thread updates the shared resource, another thread may also make some modifications to the shared resource. For example, imagine if multiple employees are using a database, and let’s say 3 employees add a new record at index 51, at the same time. This would cause a collision.
Thus, to avoid such collisions we can lock the execution of a thread on a particular resource till the thread has come to completion, using the locking mechanism. Consider an example:
import threading
starting_number = 0
def add_to_file(occurrence):
global starting_number
for x in range(occurrence):
starting_number += 1
computation_1 = threading.Thread(target=add_to_file, args=[500])
computation_2 = threading.Thread(target=add_to_file, args=[500])
computation_1.start()
computation_2.start()
computation_1.join()
computation_2.join()
print("The number is now:", starting_number)
The output would be:
![]()
Now let’s change the arguments given to a much larger number (7-digit number), as shown below:
computation_1 = threading.Thread(target=add_to_file, args=[5000000]) computation_2 = threading.Thread(target=add_to_file, args=[5000000])
The output would be:
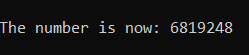
We would expect the result to be an 8-digit number, specifically 10,000,000. However, what is happening here is that for a larger computation there are a lot of times when the computation of one thread would overwrite the value of the other thread.
Now using the Lock object we can lock a thread so that only one of the two threads has access to the shared resource one at a time.
import threading
starting_number = 0
def add_to_file(occurrence, lock_thread):
global starting_number
for x in range(occurrence):
lock_thread.acquire() # locks thread
starting_number += 1
lock_thread.release() # releases thread
# Lock Object Variable
thread_lock = threading.Lock()
computation_1 = threading.Thread(target=add_to_file, args=[5000000, thread_lock])
computation_2 = threading.Thread(target=add_to_file, args=[5000000, thread_lock])
computation_1.start()
computation_2.start()
computation_1.join()
computation_2.join()
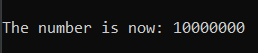
print("The number is now:", starting_number)
The result would be:
Lock Object
A lock on a shared object can be in one of two states, ‘locked’ and ‘unlocked’. There are two primary functions that we can use with the Lock object, and they are the acquire() and release().
We use the acquire() function to change the state (to lock or unlock) of a resource. If a resource is unlocked then it is locked by our current thread, however, if it is locked by another thread then the current thread waits (or the current thread’s lock is blocked) till the other thread unlocks it.
The release() function changes the state of a resource from locked to unlocked.
In the above example, the second thread does not wait till the first thread completes its execution but both are executed at the same time. The first thread locks the variable, adds 1 to it, and then releases it. But since we have also called acquire() for the second thread as well, it waits for the first thread to unlock it and then locks the variable for itself.
RLock
When we use the Lock object, there is an issue that we face. The Lock object once it locks on a resource from let’s say Thread 1, the lock then blocks all attempts from any thread (Thread 2, 3, … n) to access it and it also includes the thread that locked it i.e., Thread 1. Thus, we use RLock also known as reentrant lock, to prevent undesired blocking of access to shared resources.
Consider an example:
class RLock_Class:
def __init__(self):
self.item_1 = 3
self.item_2 = 5
self.thread_lock = threading.RLock()
def alter_first_item(self):
self.thread_lock.acquire()
self.item_1 = self.item_1 + 2
print("First Item Function:", self.item_1)
self.thread_lock.release()
def alter_second_item(self):
self.thread_lock.acquire()
self.item_2 = self.item_2 + self.item_1
print("Second Item Function:", self.item_2)
self.thread_lock.release()
def alter_both_items(self):
self.thread_lock.acquire()
self.alter_first_item() # Lock Object would be blocked here but not RLock
self.alter_second_item()
print("Both Items Function:", self.item_1, self.item_2)
self.thread_lock.release()
object_1 = RLock_Class()
object_1.alter_both_items()
The output would be:
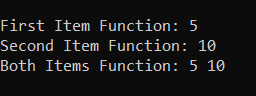
In the above code, if we try to use the Lock object, the program will keep waiting as the function “alter_both_items()” first places a lock on the resources. Then when we call “alter_first_item”, it also tries to place a lock on the resources. This causes a conflict which causes the program to wait infinitely. This can be avoided when we use an object of the class “RLock_Class”, which prevents unnecessary blocks of access to shared resources. Using RLock, python will allow us to create another lock using the same thread.
What have we learned?
- How can we lock a thread?
- When do we have to lock a thread?
- What are the two objects we can use to lock a thread?
- What are the two functions we can use for the Lock and RLock objects?
- What is the difference between Lock and RLock?